|
Data carving options options
|   |
|
Data carving options options
| |
Data carving is processing data based on file content rather than using a file system. The disk, or the area selected will be scanned and when a possible file start is found, and new file will be generated, and placed in a subdirectory based on file extension. When possible, the file will be analysed further to generate a meaningful file name, or file date.
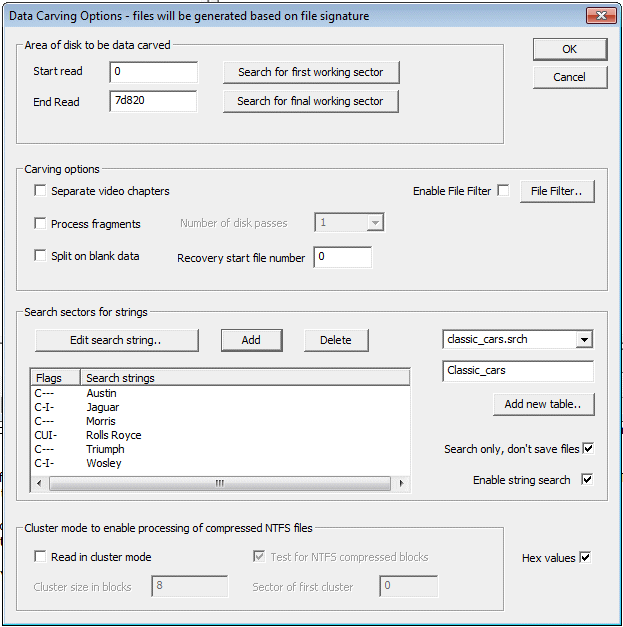
There are 4 sections to the data carving process
Area to carve
The carving process can either carve the complete disk (by default) or just select a specific area. One reason to limit the search could be if the final area of a disk is known to be blank. It can also be used to just carve a particular partition. The sectors nunbers are entered (in hex or decimal). The search for first or final working sector is typically used for CDs or DVDs to establish the are of the disk that can be read on unfinalised disks
Carving options
Separate Video Chapters
This mode is used to process video disks - in particular mini dvds. When it finds an MPEG file, it will then determine if a new chapter has been started, and then start a new MPEG file. Without this option, a DVD could end up producing just a single MPEG and this makes navigation (next chapter, etc) difficult.
Process fragments
This is a very power option when dealing with JPEGs and AVI files from a disk that has been fragmented. At the end of the original disk scan a list of possible fragmented files is displayed. At this point they can be selected for processing, and hopefully reconstruction the fragments found.
Split on blank disk
This will treat blank sectors, ie those filled entirely with zeros as the end of a file. Some files do have data that is blanks, so this option should be used with caution.
Recovery start file number
If it is necessary to restart the data carving process, by default the file naming will start recover0000.xxx. By setting the recovery start number to a higher value, the file naminmg can be set to start for instance at 10000, rather than 0. This means that multiple carving runs can save all the files in the same directory area, without a possible naming conflict. The number is always decimal.
Skip verify
An important feature of CnW data carving is that it verifies files, and with common file types it will try and create a more meaningful file name, or add the date etc. Very occasionally this can go wrong and maybe cause the software to crash. To avoid this, the verification can be disabled. This automatically also locks out any possible file defragmentation. When ever possible, files should be verified.
File filter
The file filter option can be used to select (or skip) certain catagories of files
Cluster modes
When the cluster mode is enabled, the program will only look for possible file starts at the start a logical cluster. When there are 8 sectors to a cluster this means that it will only look every 8 sectors, and this will help reduce the number of false file starts. The program will automatically set the location and size of the clusters, but these values can be overridden. For NTFS disks that have been compressed, the test of NTFS compressed clusters will test each cluster to see if compressed. If it has been compressed, the program will read 16 clusters and try and decompress the data. On a non fragmented disk, the results will be good, but on a heavily fragmented disk, the results may be very variable. For more details on clusters see Disk Clusters
The search string option will search for entered strings when scanning the disk. There is an option do just a search, and not save any files at the same time. This is a forensic log option.
Multiple sets of search strings can be saved on the system is separate tables. To create a new table, enter a name in the box above 'Add new table..'. At that point a new table will be created and strings can be added. There is no limit on the number of strings, but the speed of searching is influenced by the length of the shortest string being search for. The longer the string, the quicker the search.